

Palabra de candidato: el uso de la tecnología para analizar el discurso de los presidenciables guatemaltecos

El conjunto de tecnologías disponibles en la actualidad posibilita analizar los discursos de los candidatos de formas novedosas. Vale la pena hacerlo, pues pronto estaremos inmersos en un nuevo proceso electoral y la cacofonía de discursos y promesas de candidatos volverá a llenar el ambiente. Este análisis apoyado en la tecnología es un trabajo en progreso y, para explicar cómo pienso abordarlo, empezaré contándoles lo que me motivó a intentarlo en 2019.
En las elecciones generales de Guatemala en 2019, se postularon 19 candidatos a la presidencia. Un contendiente más quedó fuera de la boleta por disposición del TSE, así que inicialmente eran 20. La confusión que se generó por tal cantidad de opciones era comprensible. Los discursos proselitistas intentaron diferenciar a cada candidato del resto, pero fue difícil compararlos entre tantos.
Los discursos proselitistas intentaron diferenciar a cada candidato del resto, pero fue difícil compararlos entre tantos.
Quienes contaban con mayor financiamiento de campaña hacían más ruido. Los que sentían que no tenían posibilidades de ganar se daban el lujo de hacer ofertas descabelladas e irrealizables. En contraposición, los que aparecían más alto en las encuestas eran cuidadosos con lo que ofrecían para no poner en riesgo su ventaja. Eslóganes, fotografías, colores y cantos inundaban los medios. A falta de algo mejor, se esperaba que estos influyeran en la intención de voto.
Entonces llegaron los foros y los debates. Como no era práctico enfrentar a los 20 candidatos al mismo tiempo, en uno de ellos los dividieron en 4 grupos que discutieron los mismos temas en 4 fechas distintas. Eran ocasiones espléndidas para escuchar los planteamientos y apreciar las diferencias en opiniones y planes. Nada novedoso hasta aquí salvo por un detalle tecnológico. Los organizadores decidieron que estos eventos eran demasiado importantes para quedar en una sola emisión televisiva y los colocaron en YouTube.
Existen grabaciones de debates previos a los de 2019 y también se encuentran en YouTube. La diferencia está en la madurez de la tecnología y su grado de adopción por parte de la población guatemalteca. Por una parte, los videos de elecciones anteriores, de 2015, por ejemplo, son de baja calidad y suelen comprender solo porciones de los eventos. Por otra parte, las herramientas de inteligencia artificial de YouTube se encontraban mucho menos avanzadas. En 2019, la transcripción de todo lo dicho en los foros estuvo disponible casi inmediatamente. Lo que cada candidato planteó, con el minuto y segundo en que lo dijo, se podían revisar y descargar sin mayor problema.
Existen grabaciones de debates previos a los de 2019 y también se encuentran en YouTube. La diferencia está en la madurez de la tecnología y su grado de adopción por parte de la población guatemalteca.
No es posible explicar demasiados detalles ahora. Lo fundamental es lo siguiente: por primera vez dispusimos de una grabación completa de todos los candidatos, en igualdad de condiciones, abordando los mismos temas, contestando preguntas similares y con el texto de sus respuestas transcrito digitalmente —dividido en pequeñas frases, cada una con el minuto y segundo en que habían sido dichas—. Era cuestión de tiempo para que alguien tomara esos datos y comenzara a analizarlos. Yo hice eso y los resultados se revelaron interesantes.
Interfaz de usuario de la base de datos de textos de discursos de candidatos con herramientas de análisis.
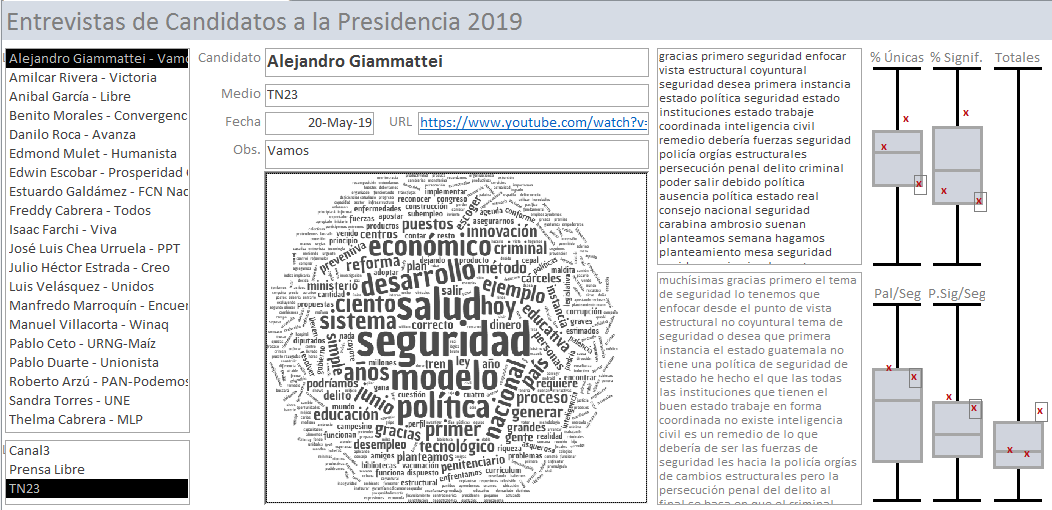
Discursos como datos
Con todos esos textos en una base de datos y las marcas de tiempo, hay varias características del discurso que se pueden estudiar, por ejemplo, la velocidad de quien habla. Se toma el total de palabras dichas y se divide entre el número de segundos usado para decirlas y se tiene una primera aproximación en palabras por segundo. Otra métrica calculable es el porcentaje de palabras significativas, que resulta de filtrar vocablos como artículos, conectores y otras que aportan poco —que en la jerga de minería de datos se conocen como stop words o palabras vacías—. Un candidato podía estar hablando rápido, pero, si el porcentaje de palabras significativas era bajo, quizá no estaba diciendo mucho. En la misma línea, es posible contar las palabras únicas utilizadas para obtener su porcentaje. En principio, un candidato más culto usaría un lenguaje más abundante y, por ello, una mayor cantidad de palabras únicas.
Un candidato podía estar hablando rápido, pero, si el porcentaje de palabras significativas era bajo, quizá no estaba diciendo mucho.
El análisis podía hacerse más fino. Asumiendo que cuando un candidato toca un tema con poca convicción, quizá porque no lo domina o no le es familiar, esa inseguridad le hará hablar más lento que lo habitual, entonces se puede intentar detectar aquellos tópicos en los que había hablado más despacio para identificar sus posibles debilidades. Otros refinamientos consistieron en ubicar a cada candidato con respecto a la media en cada métrica. Por ejemplo, algunos estaban por encima de la media en velocidad al hablar, pero por debajo en porcentajes de palabras significativas o palabras únicas.
Asumiendo que cuando un candidato toca un tema con poca convicción, quizá porque no lo domina o no le es familiar, esa inseguridad le hará hablar más lento que lo habitual, entonces se puede intentar detectar aquellos tópicos en los que había hablado más despacio para identificar sus posibles debilidades.
Cuando se realizaron nuevos foros y debates, la base de datos se enriqueció. También fue posible integrar los textos de entrevistas publicadas en medios escritos. Lo importante era disponer de fuentes homogéneas para todos los candidatos. Incluir material que solo cubriera a uno o pocos de ellos podría introducir sesgos.
Explicación de los diferentes elementos del interfaz de usuario de la base de datos de discursos. Estos elementos facilitan el análisis y la comparación entre candidatos.
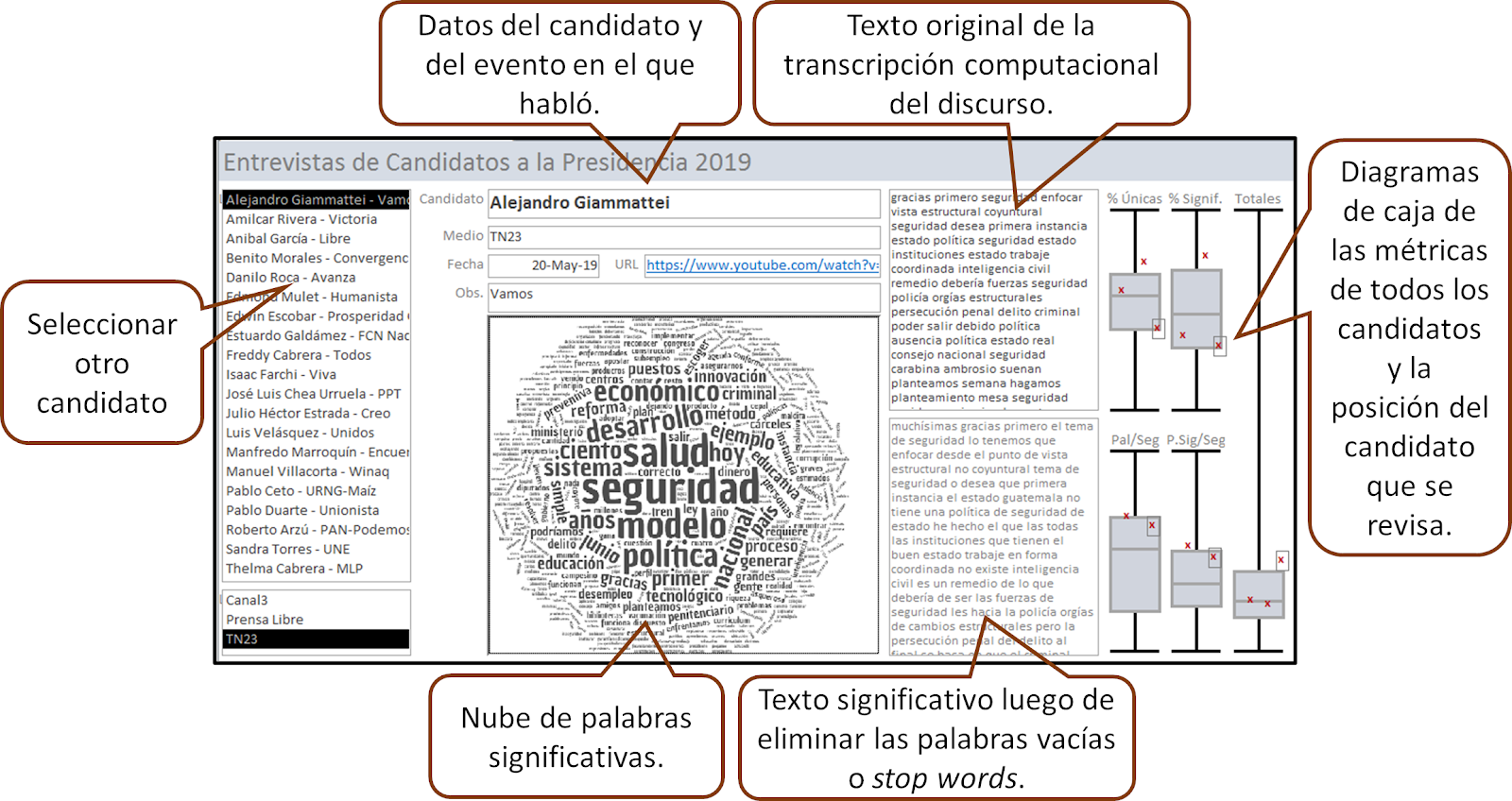
Categorías de oradores
El análisis de datos condujo a clasificar a los candidatos en 7 categorías: veloz, eficaz, sobrio, cantinflesco, soso, calmado y lento. Los veloces decían muchas palabras por segundo con alto porcentaje de significativas. Los lentos estaban al otro extremo en velocidad con porcentaje de significativas no demasiado alto.
El análisis de datos condujo a clasificar a los candidatos en 7 categorías: veloz, eficaz, sobrio, cantinflesco, soso, calmado y lento.
Los cantinflescos eran peculiares. Combinaban alta velocidad con bajo porcentaje de significativas; hablaban mucho, pero decían poco. Tres candidatos cayeron en esta categoría.
Me habría gustado un debate entre los dos que cayeron en la categoría de veloces. Su discurso era difícil de seguir en ocasiones, pero su estilo y fluidez les daban un aire intelectual agradable. Los de las categorías soso, calmado y lento eran los menos atractivos.
Los de las categorías soso, calmado y lento eran los menos atractivos.
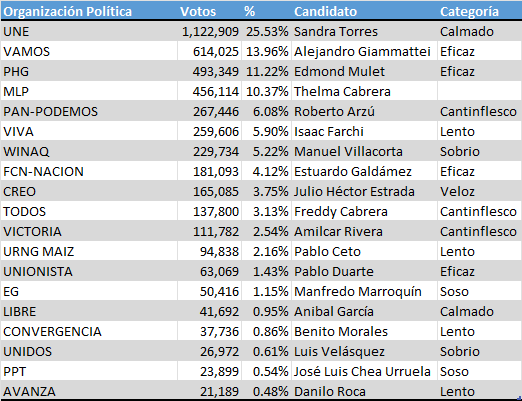
De momento no sabemos si la categoría en la que cae un candidato está correlacionada con la cantidad de votos que obtendrá. Puede que los guatemaltecos prefieran alguna entre ellas. Tampoco lo sabemos. La tabla 1 muestra la lista de candidatos ordenada por la cantidad de votos que obtuvieron en la primera vuelta de las elecciones de 2019 y la categoría en que estuvieron clasificados según el esquema explicado aquí. El nuevo proceso electoral que está por iniciar proveerá nuevas luces.
Tabla 1: Resultados de la primera vuelta de las elecciones presidenciales de 2019 en Guatemala. La columna a la derecha muestra la categoría en la que estuvo clasificado cada candidato.
AVISO IMPORTANTE: El análisis contenido en este artículo es obra exclusiva de su autor. Las aseveraciones realizadas no son necesariamente compartidas ni son la postura oficial de la UFM.
